
How to Build a Python Sitemap Generator for URL Scraping for FREE?

1- Using Google Sheets (Quick and Easy)
2- Using Screaming Frog (A Bit More Complex)
3- Using Python & Custom Script (For Large Sitemaps)
Watch the video or keep on reading for the overview!
How to Automate Scraping Data from a List of URLs
Why Not Just Copy-Paste?
If you’re dealing with small sitemaps (40-50 URLs), manually copying the URLs might work. But once you’re dealing with hundreds or thousands of URLs, this method becomes inefficient, error-prone, and slow. Additionally, sitemaps often have URLs nested under others—something you can’t capture by simply copy-pasting. This is where automated methods come into play.
Method 1: Using Google Sheets (Quick and Easy)
Step-by-Step:
- Open a Google Sheet and select an empty cell
- Paste the following formula to quickly pull URLs from the sitemap
=IMPORTXML("YOUR_SITEMAP_URL","//*[local-name()='loc']")- Result: Google Sheets will pull all URLs from the sitemap. Notice that the result might include extra URLs (like media files) that are nested under each URL, which is why you can’t get them just by copy-pasting.
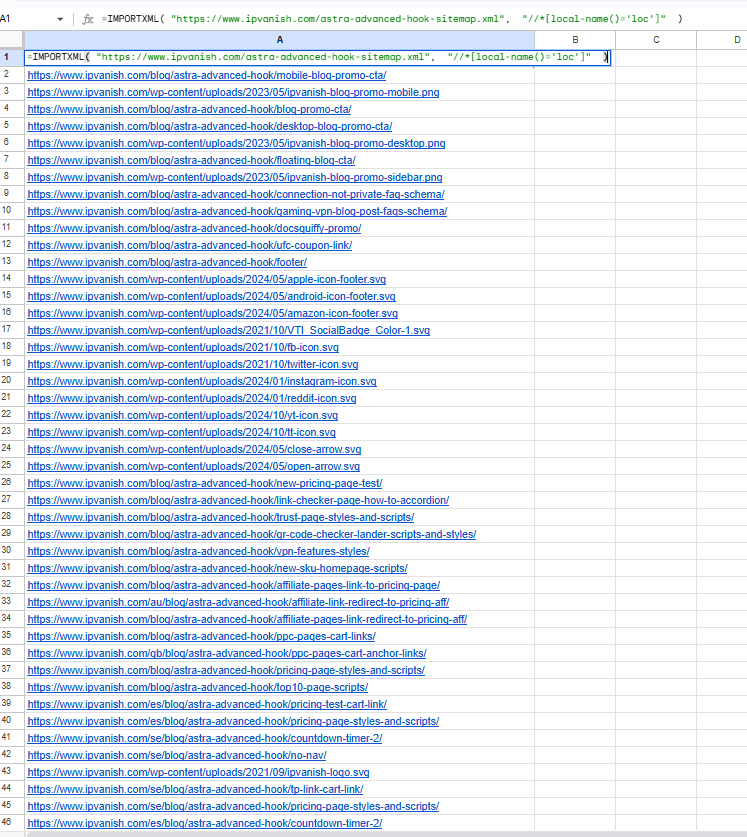
For instance, you may notice 1608 URLs being pulled, though the sitemap itself has 795 URLs—this happens because Sheets also includes images, PDFs, and other assets linked under each page.
Method 2: Using Screaming Frog (A Bit More Complex)
Step-by-Step:
1- Download and Install Screaming Frog from the official website.
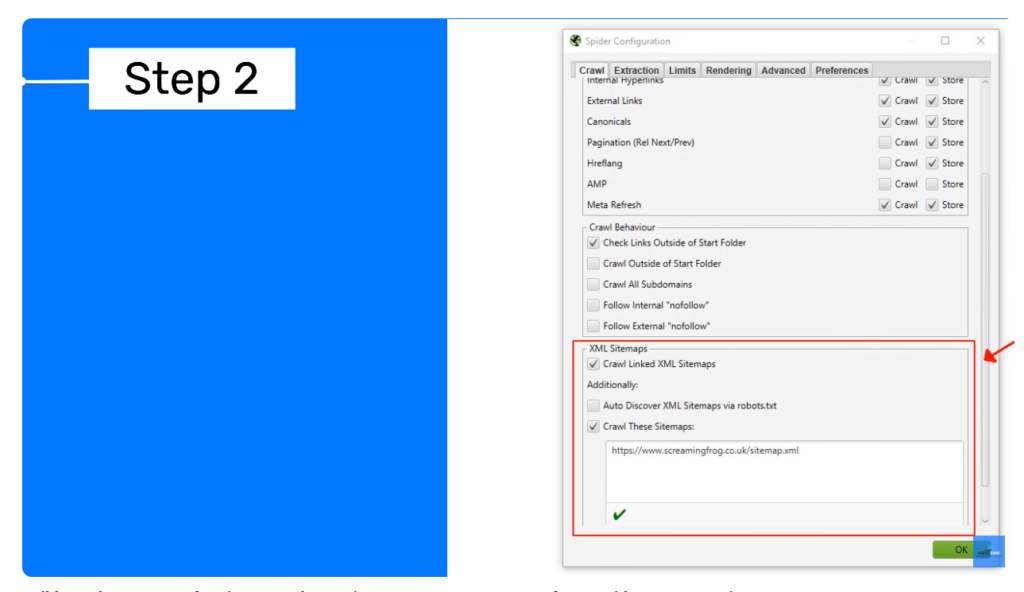
2- Go Configuration > Spider > Crawl and select “Crawl Linked XML Sitemaps.”
3- Manual or Auto Discovery: You can enter the sitemap URL manually or let Screaming Frog auto-discover it.
4- Start the Crawl: Open the spider, enter the website URL, and click “Start”.
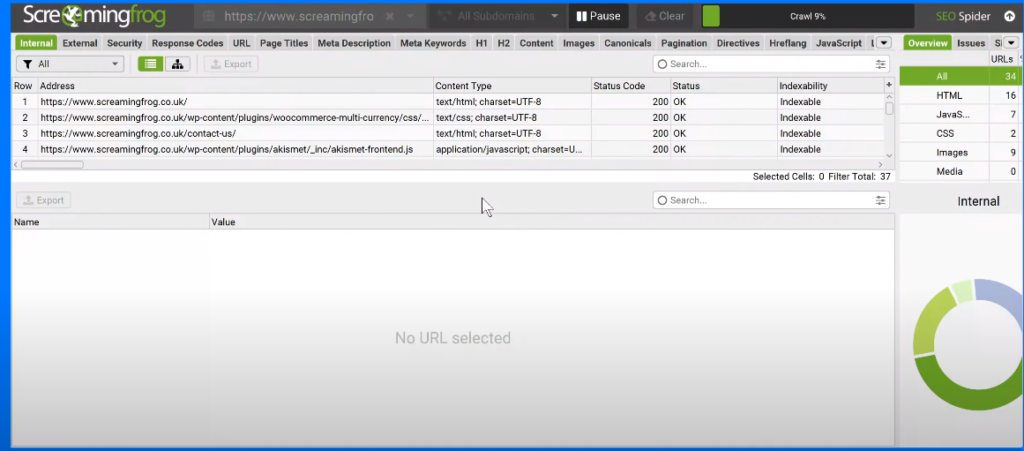
5- Wait for Completion: Wait until it reaches 100% and your data will be ready.
6- Filters: Use Screaming Frog’s 7 filters in the Sitemaps tab to group and analyze data by type.
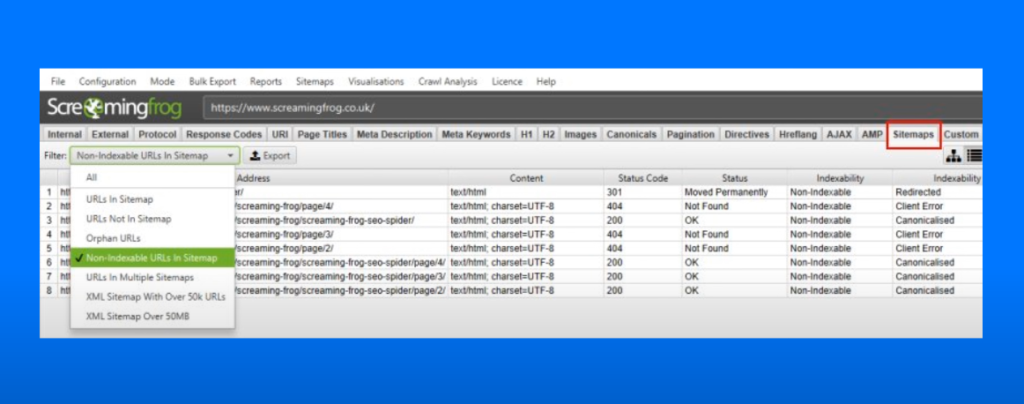
With Screaming Frog, you can deeply analyze the content structure, filter out duplicate pages, and detect issues within the sitemap.
Method 3: Using Python & Custom Script (For Large Sitemaps)
Perfect for:
- Large sitemaps (1000+ URLs).
- Requires no local Python installation. Google Colab makes it easy to run the script directly from the cloud.
Step-by-Step:
1- Go to Google Colab. Open Google Colab, which lets you run Python scripts in the cloud without installing anything and create a new notebook.
2- Copy-paste the custom Python script (provided below).
# ========================
# 1) Install dependencies
# ========================
!pip install --quiet requests gspread google-auth google-auth-oauthlib google-auth-httplib2
import requests
import xml.etree.ElementTree as ET
import gspread
from google.colab import auth
from google.auth import default
from google.colab import files
# ======================================
# 2) Function to extract URLs from sitemap
# ======================================
def extract_sitemap_urls(sitemap_url):
"""
Fetches the XML sitemap from the given URL, parses it,
and returns a list of extracted URLs (<loc> elements).
"""
# Use a browser-like User-Agent to reduce the chance of being blocked
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/109.0.0.0 Safari/537.36'
}
try:
# Fetch the sitemap
response = requests.get(sitemap_url, headers=headers, timeout=15)
response.raise_for_status()
# Parse the XML
root = ET.fromstring(response.text)
namespace = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
# Find all <url> elements and extract <loc> text
urls = []
for url_element in root.findall('ns:url', namespace):
loc = url_element.find('ns:loc', namespace)
if loc is not None:
urls.append(loc.text)
return urls
except requests.exceptions.RequestException as e:
print(f"Error fetching sitemap: {e}")
return []
# =========================
# 3) Authenticate to Google
# =========================
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
# =====================================
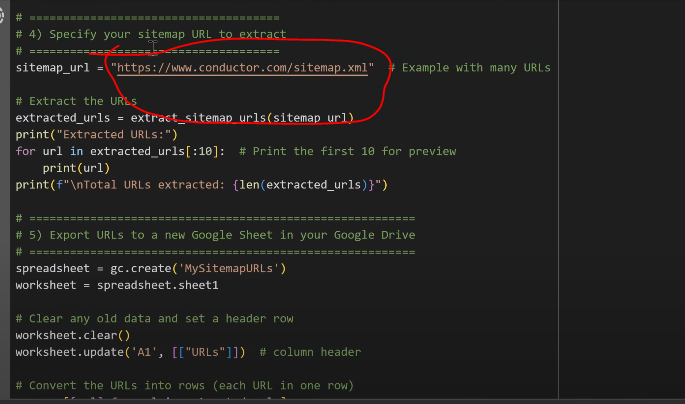
# 4) Specify your sitemap URL to extract
# =====================================
sitemap_url = "https://www.conductor.com/sitemap.xml"
# Extract the URLs
extracted_urls = extract_sitemap_urls(sitemap_url)
print("Extracted URLs (first 10):")
for url in extracted_urls[:10]:
print(url)
print(f"\nTotal URLs extracted: {len(extracted_urls)}")
# =========================================================
# 5) Export URLs to a new Google Sheet in your Google Drive
# =========================================================
spreadsheet = gc.create('MySitemapURLs')
worksheet = spreadsheet.sheet1
# Clear old data and set a header row
worksheet.clear()
worksheet.update('A1', [["URLs"]])
# Convert URLs into rows and update
rows = [[url] for url in extracted_urls]
worksheet.update('A2', rows)
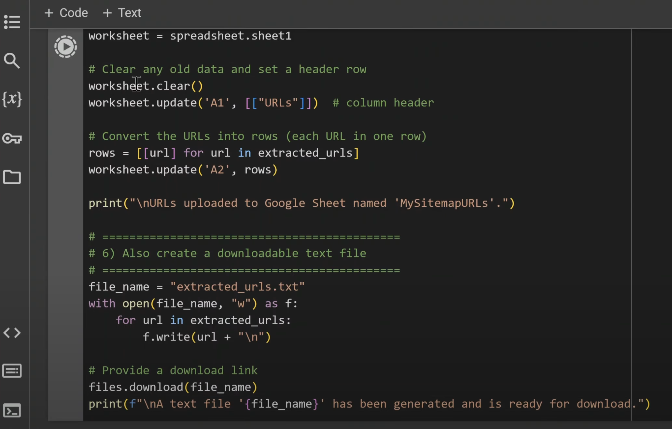
print("\nURLs uploaded to Google Sheet named 'MySitemapURLs'.")
# ============================================
# 6) Also create a downloadable text file
# ============================================
file_name = "extracted_urls.txt"
with open(file_name, "w") as f:
for url in extracted_urls:
f.write(url + "\n")
files.download(file_name)
print(f"\nA text file '{file_name}' has been generated and is ready for download.")
3- Run the Script: Paste in your sitemap URL (we used conductor.com in this example), hit Play, and the script will pull all URLs within seconds (or an hour for large sitemaps).
4- Save the Output
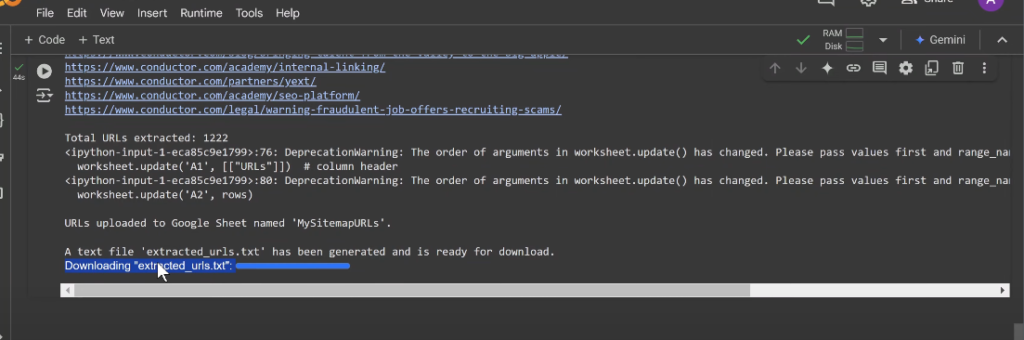
- The script saves the URLs to a notepad document.
- It also saves a file named “MySitemapURLs” in your Google Drive once you grant the necessary permissions.
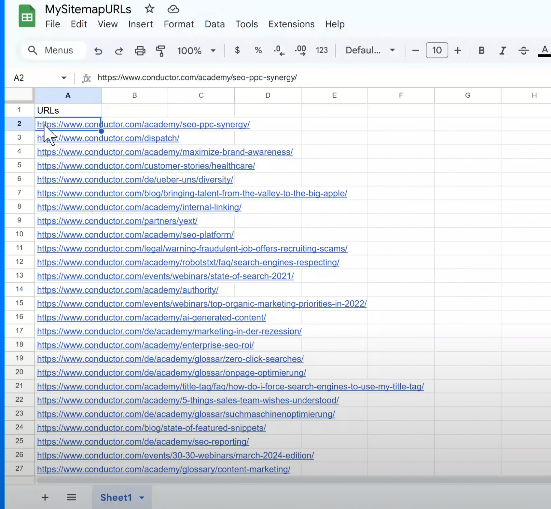
Output Data: https://docs.google.com/spreadsheets/d/1m_4Zfpz_YVAHy0MRCBe7wIkVgyVnFWPaTdAeNJ2u34o/edit?usp=sharing
Customization: The script is flexible, allowing you to adjust things like file formats or the user-agent string if needed.
Competitor Research (AI-driven)
After gathering the URLs, run a ChatGPT competitor analysis (as seen in our previous tutorial) to evaluate the SERP for each URL and gain valuable SEO insights. This AI-driven analysis with ChatGPT can quickly give you a competitive edge in search rankings.
Here’s a competitor research prompt to kick things off:
- Analyze the Search Engine Results Page (SERP) for the 1223 URLs to understand their ranking.
- Investigate “People Also Asked” sections and featured snippets.
- Review Ranking Strategies: Focus on each competitor’s presentation, narrative style, and unique insights.
- Identify Key NLP Keywords: Discover the most relevant keywords and related terms from each competitor.
Create a competitor research table outlining all findings to refine your SEO strategy and out-rank your competitors.
Wrapping Up
These three methods are perfect for automating sitemap scraping and analyzing competitor sites at scale. Whether you’re a marketer or an SEO professional, they can save you time, uncover hidden opportunities, and help craft a content strategy that positions you for success.
Got Questions?
Comment below or reach out to us at info@digitalonian.com. We’re happy to help!